Table of Contents
The main advantage of using a MOM for replication purposes is that you can achieve loosely-coupled distributed systems. The Messaging Oriented Middleware (MOM) is generic and can therefore be used in many different use-cases. For example, in the case of the XmlBlaster it is currently used to solve problems for Business to business (B2B) applications, for monitoring and administration of industrial systems such as process industry, for satellite systems, for banking or aereospace control.
A MOM normally also offers strong compression, failsafety, modern security concepts, maximal scalability and much more.
You could basically say that the more complex and varied the replication environment is, the best suited a MOM approach is. Suppose for example you may need to use odd communication protocols, if you need to modify or filter data according to some business rules where such rules are specific to the individual destinations of the replication, then using a MOM is often the only technically- and economically reasonable solution left.
XmlBlaster is an Source Message oriented Middleware (MOM) based on java. There are client libraries available in many programming languages such as Java, J2ME, C and C++, C# and many other scripting languages such as php, javascript, python and many more . For languages where such libraries are not implemented, access interfaces are provided on different communication protocols such as CORBA, XML-RPC, SOCKET, HTTP, EMAIL . Monitoring is also supported following the JMX standard . Standard Monitoring Tools can be used or you easly can taylor your own monitoring applications by using some of the highly customizable adaptors offered.
We use the Publish/Subscribe paradigm for the replication. This way the source of the replication is entirely de-coupled from the destinations it feeds. In other words the source is configured as an own system, totally unaware about which the destinations are. One of the obvious benefits is that the source can work totally independently from the destinations and vice versa. In fact the source and the destinations don't need to be available to each other at the same time. Also there is no need to re-configure the source if you add or remove some destinations.
For cases where you only need a partial replication, i.e. where you only need a limited portion of the original data, for example a subset of tables belonging to a schema or a limited number of schemas, it can be done easely. Also if some of the destinations need a modification of the data, for example if the the original table is called something and the replica table must be called somethingelse this can be done by a specific configuration change. Also if you need to write data from one column in a table to another column in the same table this can be simply configured in one line.
For more complex modifications you can write your own simple plugin having the characteristics which best suite your needs.
Basically three kind of actors are involved in the replication process:
Source
XmlBlaster
Sink or Destination
The Source, which also can be identified as the Master , is the data which will be replicated. The xmlBlaster is the MOM responsible for the transport and delivery of the data to the Destinations. The later are also called Sinks of the replication. We will normally be dealing with Single Master / Multiple Slaves replication, meaning there is a single source but there can be multiple destinations. The destinations can be plugged in and out dynamically. This approach excludes conflicts and eliminates this way the danger of using error prone and complex conflict resolution algorithms.
![[Note]](images/note.png) | Note |
|---|---|
It is possible to use this replication in a Multimaster approach but this can only be safely done if the business logics are such that no conflict can occur in the replication of the data. This is the case for situations where the data for which individual masters are responsible never overlap each other. |
The following are the basic steps in our Replication Workflow:
Synchronous Detection of a change to be replicated
Synchronous Queueing of the change in a specific table
Asynchronous (polled modus) Publishing of the change
Distribution of the replication data
Storage of the replicas
Step 1 and 2 are executed in the thread which initiated the change on the source database. This is normally the thread of the application making a change on the database. The code executed in these steps is PL/SQL. It is basically a set of functions, triggers, tables, views and sequences which we further will call the DB Resources . Particularly important in this context is the table which works as the outgoing queue. This is the interface to the publishing step (step 3). This table is called ${replication.prefix}items where ${replication.prefix} is a configuration parameter identifying the replication source. This table contains all the changes having to be replicated:
CREATE TABLE
INSERT
UPDATE
DELETE
DROP TABLE
ALTER TABLE
Step 3 occurs outside the database. It is an asynchronous step meaning some application polls and checks if changes have occurred on the ${replication.prefix}items table. If such a change occurred it will be published. More specifically this misterious application is an xmlBlaster Client called DbWatcher . Such client can either run inside the same JVM as the XmlBlaster server as a native client plugin, or it can run as a standalone application.
The distribution of the generated messages (Step 4) is handled by the XmlBlaster based on the Publish/Subscribe paradigm. More simply on this approach: if you want a message you have to manifest your interest by subscribing the same way as you would do when you subscribe to a magazine. The publisher, as the author of an article in that magazine, has not the slightest idea about who will read what he published.
The Subscribers get the replication data in an update event. They analyze and process the data according to the needs finally store it in the slave destination database. These clients are called DbWriter and can -as for the case of the DbWatcher- either run inside the server's JVM or as standalone application.
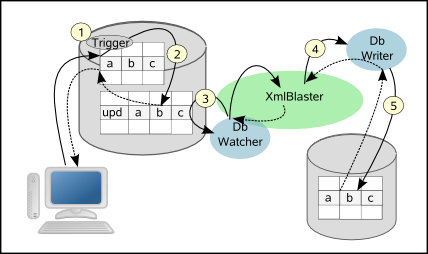
Replication DB Resources, DbWatcher XmlBlaster and DbWriter are the components used for the replication.
When starting a new system you need to trigger an Initial Update
| Note |
|---|---|
This step is performed for each Destination. It implies processing on the master-, on the xmlBlaster- and on the slave-side. In case you get inconsistencies on your replicas or for other reasons you can always invoke an initial update again. |
| Note |
|---|---|
The Master is a lazy fellow which does not perform any work until it is explicitly asked for. Until somebody really triggers a first initial update, nothing happens. |
Since there are cases where it can be difficult for clients to communicate to the server, and for monitoring and administration purposes, it is convenient to centralize the most of the logics involved in replication on the server side. For this reason every Slave client has a proxy on the server side. Such proxies are called ReplSlave . All ReplSlaves are owned and administered by a ReplManagerPlugin . Whenever an administrator requests an operation on the a Slave, it is not the real slave (The DbWriter) which works, but this server side proxy object.
When using our replication each XmlBlaster instance contains one and only one ReplManagerPlugin. Each such object has exactly one MBean representing the replication: the ReplManagerPluginMBean. One ReplManagerPlugin can administer several replication sources: n DbWatcher and several replication destinations: m DbWriter .
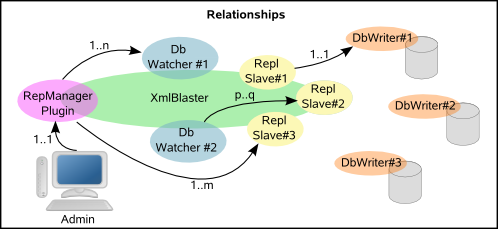
Every DbWriter is always represented on the server side by a ReplSlave proxy. This is true even if the DbWriter is running as a native client in the XmlBlaster's jvm. We can therefore consider this as a one to one relation. Every DbWriter can receive its data from one or more DbWatchers. Normally it only gets data from one single DbWatcher but if conflicts are avoided it can receive data from several DbWatchers. On the other hand, every DbWatcher can feed one or more DbWriters so we have a many to many relation here. In the drawing this is represented by a p..q relation. Here p is a subset of n (for the DbWatchers) and q is a subset of m (for the DbWriters).
The central part of the replication is the ReplManagerPlugin. This is the instance the administrator interacts with. The ReplManagerPlugin knows all active DbWatchers, i.e. it holds a map of all masters implied in replication. Every such DbWatcher is identified with a key defined in its configuration as replication.prefix . Not all DbWatchers are must necessarily be replication-masters, they could serve other purposes. If they have to serve as replication-masters however, they need to have such a replication.prefix property defined.
Every DbWatcher serving as a replication master registers itself to the ReplManagerPlugin shortly after having connected or reconnected to the XmlBlaster and is unregistered when it is disconnected or when it temporary looses the connection to the XmlBlaster. The registration and un-registration happens by means of a point-to-point message sent to the ReplManagerPlugin. For this, and other reasons, the DbWatcher must be available when starting or restarting a replication.
| Note |
|---|---|
Currently the ReplManagerPlugin has an hardcoded session name which is known to the DbWatcher. So this is currently not configurable. |
The DbWriters serving as slaves in the replication are also known to the ReplManagerPlugin. As for the DbWatchers, also here a map is hold. There are however some differences: First the ReplManagerPlugin does not really communicate with the real slave. It communicates with its server-side proxy, that is the ReplSlave associated to the involved DbWriter.
The second difference is the key: here the key is the relative session name of the DbWriter (for example client/Fritz/1 ).
The third difference is the way the registration is made: This occurs when the DbWriter connects to the xmlBlaster for the very first time. Since it is a persistent connection it never disconnects (unless it will leave the replication definitively). All DbWriters serving as replication slaves must define as the dispatch plugin the ReplManagerPlugin.
The ReplManagerPlugin listens to the Connection events and the subscription events and knows thereby when a new replication slave is available. When this is the case, it creates the proxy object (the ReplSlave). When the DbWriter subscribes to receive replication data, the ReplManagerPlugin detects it and initializes the proxy object. From now on the proxy is ready to work.
| Note |
|---|---|
In reality it is not the DbWriter which makes the subscription. Subscriptions are done on behalf of the relatively stupid DbWriter when triggering an initial update: the proxy object makes the subscription. Since the subscription is persistent, the persistence layer also replays the subscription during restart of the xmlBlaster. This way it is ensured that the receiver of the replication data is always available even if the real client is currently unavailable. Of course when the real client is unavailable, replication data is queued on the server-side until the real client is available again. |
Once they have connected, the DbWriters are always known and registered in the ReplManagerPlugin even if they are temporary unavailable. This means that you will be able to start or restart an initial update even if the DbWriter is currently off-line.