Guide on how to perform Database replication with XmlBlaster
$Revision
Abstract
The following is the documentation of the replication done with xmlBlaster. It will explain the concept and design, monitoring and configuration. It is not a detailed programming guide.
There are several formats of this documentation:
Table of Contents
List of Figures
- 2.1. Replication With XmlBlaster
- 2.2. Replication Steps
- 2.3. Relationships between entities
- 2.4. Initial Update
- 2.5. Initial Update with manual file transfer
- 2.6. File structure of Initial Update with manual file transfer
- 2.7. Sequence Diagram for insert actions
- 3.1. Replication List Page
- 3.2. Initial Update Page (simple)
- 3.3. Initial Update Page (cascaded)
- 3.4. Details Page
List of Tables
- 2.1. The Items table
- 2.2. The Tables Table
- 2.3. The Longs_Table Table
- 2.4. Description of major functions
- 2.5. Content for table. properties
- 3.1. The Items table
- 5.1. Attributes of Initial Dump message
- 5.2. Message Attributes for REQUEST_UPDATE administrative messages
- 5.3. Message Attributes for REPL_REQUEST_CANCEL_UPDATE administrative messages
- 5.4. Message Attributes for STATEMENT administrative messages
- A.1. Properties used for the replication
The Replication framework's goal is to offer the xmlBlaster user a way to replicate data from one or several source databases to one or more sink databases. The framework has been designed for a single-master / multi-slave approach. What does that mean ? It means that it does not offer any conflict resolution mechanism. In other words it is safe for cases where you have one single master database, also called the source for the replication, and one or more slaves, also called the sinks of the replication or replicas. It will generally not be safe where you have more than one master.
There are situations where this framework is currently used with more than one source for one sink, but there are limitations. For example you must ensure that the same data (at least on a row granularity) always comes from one single source.
The following are some of the features which the replication Framework offers:
Master / Multi Slave approach
Conventional one to one Replication
Replication with Data Manipulation on a per sink individual basis with no intervention on the master side
Replication with Data Filtration on a per sink individual basis with no intervention on the master side
Use of all Communication Protocols offered by XmlBlaster (even the most fancy ones)
Persistence of Messages, Fail over and guaranteed sequence of messages
Transactions are handled atomically and sent in a single Message
Possibility to interchange this with other sources/sinks for for example Meta-Databases
Plugin approach to allow business-specific functionality
Possibility to intermix different database versions and vendors
Performance tuning for specific vendors (for example for initial update)
Highly Compressed communication
Encrypted and secure replication
Unlimited number of sinks
Efficient and reliable even on unreliable networks
Table of Contents
The main advantage of using a MOM for replication purposes is that you can achieve loosely-coupled distributed systems. The Messaging Oriented Middleware (MOM) is generic and can therefore be used in many different use-cases. For example, in the case of the XmlBlaster it is currently used to solve problems for Business to business (B2B) applications, for monitoring and administration of industrial systems such as process industry, for satellite systems, for banking or aereospace control.
A MOM normally also offers strong compression, failsafety, modern security concepts, maximal scalability and much more.
You could basically say that the more complex and varied the replication environment is, the best suited a MOM approach is. Suppose for example you may need to use odd communication protocols, if you need to modify or filter data according to some business rules where such rules are specific to the individual destinations of the replication, then using a MOM is often the only technically- and economically reasonable solution left.
XmlBlaster is an Source Message oriented Middleware (MOM) based on java. There are client libraries available in many programming languages such as Java, J2ME, C and C++, C# and many other scripting languages such as php, javascript, python and many more . For languages where such libraries are not implemented, access interfaces are provided on different communication protocols such as CORBA, XML-RPC, SOCKET, HTTP, EMAIL . Monitoring is also supported following the JMX standard . Standard Monitoring Tools can be used or you easly can taylor your own monitoring applications by using some of the highly customizable adaptors offered.
We use the Publish/Subscribe paradigm for the replication. This way the source of the replication is entirely de-coupled from the destinations it feeds. In other words the source is configured as an own system, totally unaware about which the destinations are. One of the obvious benefits is that the source can work totally independently from the destinations and vice versa. In fact the source and the destinations don't need to be available to each other at the same time. Also there is no need to re-configure the source if you add or remove some destinations.
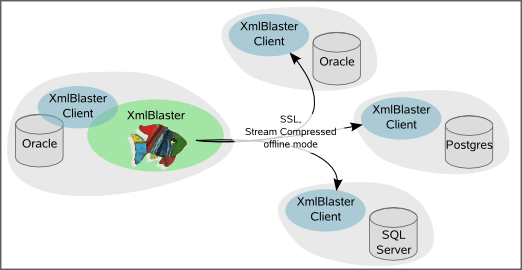
For cases where you only need a partial replication, i.e. where you only need a limited portion of the original data, for example a subset of tables belonging to a schema or a limited number of schemas, it can be done easely. Also if some of the destinations need a modification of the data, for example if the the original table is called something and the replica table must be called somethingelse this can be done by a specific configuration change. Also if you need to write data from one column in a table to another column in the same table this can be simply configured in one line.
For more complex modifications you can write your own simple plugin having the characteristics which best suite your needs.
Basically three kind of actors are involved in the replication process:
Source
XmlBlaster
Sink or Destination
The Source, which also can be identified as the Master , is the data which will be replicated. The xmlBlaster is the MOM responsible for the transport and delivery of the data to the Destinations. The later are also called Sinks of the replication. We will normally be dealing with Single Master / Multiple Slaves replication, meaning there is a single source but there can be multiple destinations. The destinations can be plugged in and out dynamically. This approach excludes conflicts and eliminates this way the danger of using error prone and complex conflict resolution algorithms.
![[Note]](images/note.png) | Note |
|---|---|
It is possible to use this replication in a Multimaster approach but this can only be safely done if the business logics are such that no conflict can occur in the replication of the data. This is the case for situations where the data for which individual masters are responsible never overlap each other. |
The following are the basic steps in our Replication Workflow:
Synchronous Detection of a change to be replicated
Synchronous Queueing of the change in a specific table
Asynchronous (polled modus) Publishing of the change
Distribution of the replication data
Storage of the replicas
Step 1 and 2 are executed in the thread which initiated the change on the source database. This is normally the thread of the application making a change on the database. The code executed in these steps is PL/SQL. It is basically a set of functions, triggers, tables, views and sequences which we further will call the DB Resources . Particularly important in this context is the table which works as the outgoing queue. This is the interface to the publishing step (step 3). This table is called ${replication.prefix}items where ${replication.prefix} is a configuration parameter identifying the replication source. This table contains all the changes having to be replicated:
CREATE TABLE
INSERT
UPDATE
DELETE
DROP TABLE
ALTER TABLE
Step 3 occurs outside the database. It is an asynchronous step meaning some application polls and checks if changes have occurred on the ${replication.prefix}items table. If such a change occurred it will be published. More specifically this misterious application is an xmlBlaster Client called DbWatcher . Such client can either run inside the same JVM as the XmlBlaster server as a native client plugin, or it can run as a standalone application.
The distribution of the generated messages (Step 4) is handled by the XmlBlaster based on the Publish/Subscribe paradigm. More simply on this approach: if you want a message you have to manifest your interest by subscribing the same way as you would do when you subscribe to a magazine. The publisher, as the author of an article in that magazine, has not the slightest idea about who will read what he published.
The Subscribers get the replication data in an update event. They analyze and process the data according to the needs finally store it in the slave destination database. These clients are called DbWriter and can -as for the case of the DbWatcher- either run inside the server's JVM or as standalone application.
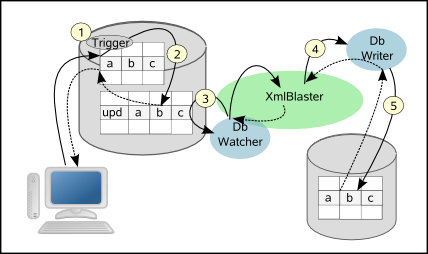
Replication DB Resources, DbWatcher XmlBlaster and DbWriter are the components used for the replication.
When starting a new system you need to trigger an Initial Update
| Note |
|---|---|
This step is performed for each Destination. It implies processing on the master-, on the xmlBlaster- and on the slave-side. In case you get inconsistencies on your replicas or for other reasons you can always invoke an initial update again. |
| Note |
|---|---|
The Master is a lazy fellow which does not perform any work until it is explicitly asked for. Until somebody really triggers a first initial update, nothing happens. |
Since there are cases where it can be difficult for clients to communicate to the server, and for monitoring and administration purposes, it is convenient to centralize the most of the logics involved in replication on the server side. For this reason every Slave client has a proxy on the server side. Such proxies are called ReplSlave . All ReplSlaves are owned and administered by a ReplManagerPlugin . Whenever an administrator requests an operation on the a Slave, it is not the real slave (The DbWriter) which works, but this server side proxy object.
When using our replication each XmlBlaster instance contains one and only one ReplManagerPlugin. Each such object has exactly one MBean representing the replication: the ReplManagerPluginMBean. One ReplManagerPlugin can administer several replication sources: n DbWatcher and several replication destinations: m DbWriter .
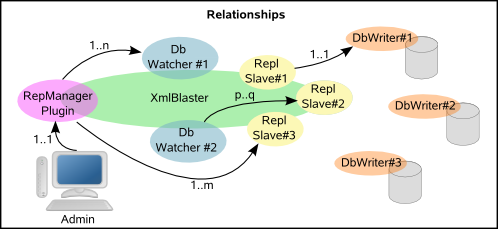
Every DbWriter is always represented on the server side by a ReplSlave proxy. This is true even if the DbWriter is running as a native client in the XmlBlaster's jvm. We can therefore consider this as a one to one relation. Every DbWriter can receive its data from one or more DbWatchers. Normally it only gets data from one single DbWatcher but if conflicts are avoided it can receive data from several DbWatchers. On the other hand, every DbWatcher can feed one or more DbWriters so we have a many to many relation here. In the drawing this is represented by a p..q relation. Here p is a subset of n (for the DbWatchers) and q is a subset of m (for the DbWriters).
The central part of the replication is the ReplManagerPlugin. This is the instance the administrator interacts with. The ReplManagerPlugin knows all active DbWatchers, i.e. it holds a map of all masters implied in replication. Every such DbWatcher is identified with a key defined in its configuration as replication.prefix . Not all DbWatchers are must necessarily be replication-masters, they could serve other purposes. If they have to serve as replication-masters however, they need to have such a replication.prefix property defined.
Every DbWatcher serving as a replication master registers itself to the ReplManagerPlugin shortly after having connected or reconnected to the XmlBlaster and is unregistered when it is disconnected or when it temporary looses the connection to the XmlBlaster. The registration and un-registration happens by means of a point-to-point message sent to the ReplManagerPlugin. For this, and other reasons, the DbWatcher must be available when starting or restarting a replication.
| Note |
|---|---|
Currently the ReplManagerPlugin has an hardcoded session name which is known to the DbWatcher. So this is currently not configurable. |
The DbWriters serving as slaves in the replication are also known to the ReplManagerPlugin. As for the DbWatchers, also here a map is hold. There are however some differences: First the ReplManagerPlugin does not really communicate with the real slave. It communicates with its server-side proxy, that is the ReplSlave associated to the involved DbWriter.
The second difference is the key: here the key is the relative session name of the DbWriter (for example client/Fritz/1 ).
The third difference is the way the registration is made: This occurs when the DbWriter connects to the xmlBlaster for the very first time. Since it is a persistent connection it never disconnects (unless it will leave the replication definitively). All DbWriters serving as replication slaves must define as the dispatch plugin the ReplManagerPlugin.
The ReplManagerPlugin listens to the Connection events and the subscription events and knows thereby when a new replication slave is available. When this is the case, it creates the proxy object (the ReplSlave). When the DbWriter subscribes to receive replication data, the ReplManagerPlugin detects it and initializes the proxy object. From now on the proxy is ready to work.
| Note |
|---|---|
In reality it is not the DbWriter which makes the subscription. Subscriptions are done on behalf of the relatively stupid DbWriter when triggering an initial update: the proxy object makes the subscription. Since the subscription is persistent, the persistence layer also replays the subscription during restart of the xmlBlaster. This way it is ensured that the receiver of the replication data is always available even if the real client is currently unavailable. Of course when the real client is unavailable, replication data is queued on the server-side until the real client is available again. |
Once they have connected, the DbWriters are always known and registered in the ReplManagerPlugin even if they are temporary unavailable. This means that you will be able to start or restart an initial update even if the DbWriter is currently off-line.
The DbResources are basically PL-SQL code which is loaded the first time the replication is started. These are loaded by the java code and executed as jdbc statements. They are read from a set of sql files which is specific for each database vendor. There is a directory for each vendor. These sub-directories reside under org/xmlBlaster/contrib/replication/setup and have the name of the database vendor. For example postgres or oracle. In these directories the important files are:
bootstrap.sql which is the file containing resources needed for the replication. This file exist for each database vendor.
createDropAlter.sql contains the triggers (and possibly functions) needed to detect CREATE, ALTER and DROP actions. This is only needed for such databases which have the possibility to add a trigger to the schema, i.e. for such which can detect by means of an event that a table has been created, dropped or altered. This is the case for oracle. Postgres on the other hand can not detect such changes. For this reason it does not have such a file.
The resources consist of the following type of database objects:
Tables
Views
Sequences
Functions
Triggers
These resources are database vendor specific. This means that their content can be different between oracle and postgres. Some of the resources can even be specific to a certain vendor, that is, they can exist for postgres but not for oracle or vice versa.
Since there can be several replications, i.e. several DbWatchers coexisting in the same database and even in the same schema, several sets of DbResources can coexist in the same database or schema. For this reason, each replication is identified by its replication.prefix attribute. This prefix will be used for the name of each DbResource. So when we speak of the ITEMS table, and we have defined a replication.prefix to be REPL_ (which by the way is the default), the real name of the resource will be REPL_ITEMS . For the sake of simplicity however we will continue to refer to it to ITEMS in this document.
There are several tables involved in the replication. The following is a short explanation. The tables are sorted in their importance order:
This is the most important table in the replication. It is the interface between the synchronous PL-SQL part of the replication and the asynchronous java DbWatcher. It is used as a queue where changes are temporary stored before the DbWatcher will pick them up and distribute them.
Table 2.1. The Items table
| Column name | Type | Description |
|---|---|---|
| REPL_KEY | NUMBER | This is a monotone increasing positive number produced by a sequence when the transaction is initiated. If a transaction is rolled back, the REPL_KEY is lost and a hole in the sequence occurs. This is the only primary key of the table. It uniquely identifies a replication change. As a replication change we understand a single operation which has to be replicated. Can never be null. |
| TRANS_KEY | VARCHAR | A string identifying a transaction within which operations to be replicated are executed. Since several operations can be executed within one single transaction, several entries in the table could share the same value. The syntax of the content depends on the database vendor. At distribution step, the DbWatcher will send entries belonging to the same transaction in the same message. Shall never be null. |
| DBID | VARCHAR | String identifying the database used as the source in the replication. Can be null and is currently not directly used for replication purposes. |
| TABLENAME | VARCHAR | The name of the table to which the entry to be processed belongs. It is the relative name of the table, that is, it does not contain the name of the schema nor the catalog. Shall never be null. |
| GUID | VARCHAR | A String identifying the unique id of the entry. It is currently used for some database vendors for specific cases. It is for example used in oracle when a table containing a LONG column has to be replicated. It could also be used to increase performance on the slave side when storing the replicas. Its content is vendor specific and can be null. |
| DB_ACTION | VARCHAR | The action to be replicated. Is either CREATE, DROP, ALTER, INSERT, UPDATE, DELETE. Is never null and is not database vendor specific. |
| DB_CATALOG | VARCHAR | The catalog to which the change belongs. Can be null and is currently not used. |
| DB_SCHEMA | VARCHAR | The schema to which the change belongs. Can be null if the database vendor does not support schemas. Is extensively used for oracle. |
| CONTENT | CLOB | This is an xml literal stored as a clob and following the syntax specified in the DbWatcher schema. This can be null depending on the ACTION performed. It is only filled on INSERT and UPDATE. In some rare cases it is null even for such operations, in which case the content must be retrieved via the GUID in asynchronous way by the DbWatcher. |
| OLDCONTENT | CLOB | This is the old content of the entry before the change. It is not null only on DELETE and UPDATE. It is used by the DbWriter to find the entry to be deleted or updated. In all other cases it is null. |
| VERSION | VARCHAR | A String identifying the version of the replication software used. Can be null. It is currently unused. |
This table contains the information on the tables which have to be replicated. This information is read from the configuration file. The properties of interest are the ones starting with tables..
Table 2.2. The Tables Table
| Column name | Type | Description |
|---|---|---|
| CATALOGNAME | VARCHAR | The name of the catalog to which the table to watch belongs. It is part of the primary key. Can never be null. If the vendor does not use catalogs, then it is a space character. |
| SCHEMANAME | VARCHAR | The name of the schema to which the table to watch belongs. It is part of the primary key. Can never be null. If the vendor does not use schemas, then it is a space character. |
| TABLENAME | VARCHAR | The name of the table to be watched. It is part of the primary key. Can never be null. |
| ACTIONS | CHAR(3) | A combination with a maximum of three characters being the upper case first letter of the action on which the trigger should be fired. Actions are Insert (I), Update (U) and Delete (D). So for example allowed entries are 'UID' or 'UI' or 'I'. If null the trigger will fire on all three actions. |
| STATUS | VARCHAR | A string identifying the status of the replication. When the entry is added to the table this is set to 'CREATING', meaning it will create the trigger but the operation is not successfully finished yet. A trigger on this table creates an entry in the ITEMS table. The DbWatcher will take the entry and add the Trigger if needed. Once the trigger has been successfully created, this STATUS flag changes to OK. This flag is also used when it must decide if the trigger has to be added. If it is not OK, it is assumed to be incorrectly added and is added again. |
| REPL_KEY | NUMBER | This is the number retrieved by the replication sequence. This will replace the sequence attribute passed in the configuration. This way the sequence information is made persistent also for entries which did not have a specific sequence on their configuration. The REPL_KEY ensures that the same sequence is loaded on each startup of the XmlBlaster. Can never be null. |
| TRIGGER_NAME | VARCHAR | The name of the trigger to be executed. This comes from the configuration and shall never be null. |
| DEBUG | NUMBER | This is currently either 0 or 1. In future further debug levels could be allowed. If 1, then debug output is written to the DEBUG_TABLE table. Can not be null. Zero means no debugging will be done for this table. |
This table has only one field RELNAME which contains the relative name of the table. It is a kind of set. If a tablename is in this table, then it is currently replicated. This is only used for vendors which can not have a trigger on the schema, i.e. which can not detect CREATE, DROP or ALTER actions on a table. In such cases, these entries -which are a snapshot- are compared by the DbWatcher with the ones of a view, which is a living dynamic content. When there are differences a change (either CREATE, ALTER or DROP) is detected.
REPL_KEY and LINE are the only columns. The first is filled by the sequence and the second is the content of the debug. This table is filled by the function debug.
Table 2.3. The Longs_Table Table
| Column name | Type | Description |
|---|---|---|
| REPL_KEY | NUMBER | This is a monotone increasing positive number produced by a sequence when the transaction is initiated. If a transaction is rolled back, the REPL_KEY is lost and a hole in the sequence occurs. This is the (only) primary key of the table. It uniquely identifies a replication change. As a replication change we understand a single operation which has to be replicated. Can never be null. |
| CONTENT | CLOB | The content of the entry to be replicated. This is filled by the java code in the DbWatcher thread. It is only used in ORACLE for tables containing at least one column being of the type LONG. In other cases this table has no significance. |
There is currently only one view used for replication purposes: COLS_VIEW. This is only needed for database vendors which do not have any possibility to add triggers which detect a table alteration. For such databases detection of these actions must occur by polling. Since the DbWatcher already polls, this detection is done by him too, before the ITEMS table is checked, a comparison between this view and a snapshot table of the same parameters taken in the previous sweep detects changed occured between the two sweeps. An example of a database where this view is used is postgres.
Currently the sole sequence used is SEQ which is used every time a unique number is needed. Its main purpose is to create the REPL_KEY which is the unique key for the ITEMS table. It is also used for the sequence of the TABLES table and for the DEBUG_TABLE table.
The functions used are several and can be different for different database vendor. We will shortly describe here the most important ones and such which are common to all vendors.
Table 2.4. Description of major functions
| Function Name | Description |
|---|---|
| NEEDS_PROT | Is invoked to determine wether the string needs base64 protection or CDATA protection. |
| COL2XML | Returns a CLOB object containing an xml literal representing the content of all columns of an entry. |
| INCREMENT | Increments the counter for the unique keys and returns one. |
When the initial update is triggered for the very first time (that is for the first slave), the replication is started. At first a check is made to see if all DbResources are available. Resources which have not been loaded yet are loaded at this stage. This is the PL-SQL Code responsible for the synchronous part of the replication. For example functions and triggers are added. Tables, functions and triggers which are available already are not loaded twice. This ensures that no ongoing replication is disturbed by an initial update of another slave.
The configuration for the tables which have to be replicated is read and compared with the entries in the ${replication.prefix}tables . If there are differences these are corrected. For example if a new table is found which was not added to the ${replication.prefix}tables yet, it is added at this stage. On the other hand, if entries are not found in the configuration file, they are removed. The associated trigger is removed too.
If the replication source is running as a native client, the configuration is read from the xmlBlasterPlugins.xml configuration file, otherwise from the master's properties file passed on the command line of the ReplicationAgent. For example if you invoke:
java org.xmlBlaster.contrib.replication.ReplicationAgent -master master.properties -slave slave.properties
Then it is read from the file master.properties file. In both cases all property names with the prefix table. are read and processed. In the xmlBlasterPlugins.xml file it could look like:
<plugin id='ReplNDBPlugin' className='org.xmlBlaster.contrib.dbwatcher.plugin.DbWatcherPlugin'>
...
<attribute id='replication.prefix'>TEST</attribute>
...
<attribute id='table.MYSCHEMA.TABLE1'>actions=IDU,trigger=TEST_TR01,sequence=3</attribute>
<attribute id='table.MYSCHEMA.TABLE2'>actions=U</attribute>
...
</plugin>
or in a property file:
... replication.prefix=TEST ...
table.MYSCHEMA.TABLE1=actions=IDU,trigger=TEST_TR01,sequence=3
table.MYSCHEMA.TABLE2=actions=U ...
The content of the properties is a comma separated list of key values. the key is separated from the value with an equality sign ('='). These list of parameters can be
Table 2.5. Content for table. properties
| Name | Mandatory | Default | Description |
|---|---|---|---|
| actions |

| IDU | These are the actions (or events) on which the trigger on the table will fire. I stands for insert, U for update and D for delete. If you choose here ID then it will only detect Inserts and Deletes, it will not detect any update. |
| trigger |
| Specifies the name to be assigned to the trigger. | |
| sequence |
| -1 | Sequence number by which the trigger is added when initializing. This value is replaced on first initialization to a sequence number gathered on the database. If you specify a negative value or nothing, then it will be loaded before any specified positive number. The sequence for properties having the same value are internally processed in a random sequence. Negative values will all be treated as -1, so internally they all will be treated in a random sequence. |
The following prerequisites must be fulfilled previously to trigger an initial update:
the XmlBlaster is running
the master of interest (DbWatcher) is currently running and reachable
the slave (DbWriter) has connected to the XmlBlaster
| Note |
|---|---|
It is not necessary that the DbWriter is currently online, it suffices that it has connected, i.e. it must have logged in once. |
![[Important]](images/important.png) | Important |
|---|---|
When connecting the DbWriter to the XmlBlaster you must specify that you want to use the DispatchPlugin[ReplManager][1.0] as a dispatcher plugin. |
The following image shows the initial update workflow graphically:
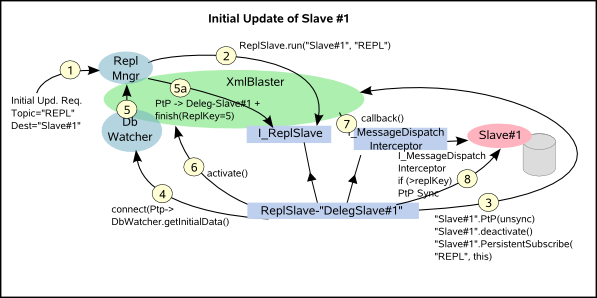
When the DbWriter connects to the XmlBlaster, the ReplManagerPlugin gets an event. If the connecting client is a replication slave, then it must have chosen the ReplManager as the dispatcher plugin. If this is the case, the ReplManagerPlugin creates a new instance of a proxy object: the ReplSlave. It is also registered in a map. It is however not initialized yet.
| Note |
|---|---|
The ReplManagerPlugin gets this event even when starting up the xmlBlaster if there are persistent connections. This way it is ensured that a slave is always represented server-side by a proxy even if it is currently off-line. |
Initial Update Request: The administrator does trigger an initial update request. This normally happens via the JMX Monitor specially designed for replication. Since the initial update establishes a marriage between a Master and a Slave you need to specify these: for the Master the replication.prefix and for the Slave the relative session name of the DbWriter.
Initializing the ReplSlave: The ReplManagerPlugin searches in its map for the given ReplSlave. When it is found it invokes the run method by passing the complete configuration of the DbWatcher. This way it does not need the information such as topic on which to subscribe since this information can be gathered from the DbWatcher's configuration. When initializing it subscribes to the relevant topic and passes the complete configuration of the DbWatcher as Client properties of the Subscription Qos. Since this is a persistent subscription, it is ensured that the ReplSlave will always know how to configure even after a server crash and even if the DbWatcher is not currently available.
Preparing the update: Once the slave is initialized the dispatcher, i.e. the framework taking care of delivering messages to the DbWriter, must be inhibited. This is to force queueing on the server side. This is needed to ensure the correct sequence of the messages to be delivered. Once delivery is inhibited, the content of the queue is completely cleared. Messages in the queue at this state are obsolete.
Requesting initial data: Everything is ready and the ReplSlave now makes a request to the newly married DbWatcher. He kindly ask the DbWatcher to send the initial data. This is done by publishing a ptp message directly sent to the DbWatcher of interest. The DbWatcher gathers this information. Several things happen here which are dependent on the configuration and on the database implementation. If it is the first update, triggers are added to the tables.
If an initial dump is requested, then it is sent directly to the DbWriter as high priority messages. Remember however that the dispatcher was temporary inhibited, which means such messages are collected and queued on the callback queue. Since they are high priority they will be the first to be delivered when the gate will be opened again.
Notifying about completion: Now the DbWatcher has done its hard work. It the time to notify the requesting part that it is OK to continue. This is done by sending a ptp message to the ReplManagerPlugin. The ReplManagerPlugin works as a dispatcher and forwards this information to the interested ReplSlave (5a).
Restarting delivery: The ReplSlave has now got the message, it knows also which is the replication key from the start and from the end of the initial update. So it basically knows if a replication change occurred during this time is obsolete or not. Having that information it is now ready to reopen the gate, that is to restart delivery of messages to the DbWatcher. This results in a status change which is visible on the monitor.
Delivery and check: Messages are now delivered and each one must be checked to see if it is obsolete. This check is also used to detect when the initial data have all been delivered. This information is then made available to the monitoring resulting in a status change.
Normal Operation: The last initial data has been delivered and the status has switched to normal operation. Messages are now delivered to the DbWriter and only a minor check of the messages is needed. Basically it is only checked if messages have already been delivered before.
In cases where it is not indicated to perform an initial update over the wire, for example in cases where the initial data is huge or the network connection slow, there is the option to transfer these data by means of files.
Per default this feature is switched off. To activate it you have to edit the customize.xsl file which resides in org/xmlBlaster/contrib/replication/monitor. You edit the line:
<xsl:param name="show.initialFilesLocation" select="'no'"/>
to be
<xsl:param name="show.initialFilesLocation" select="'yes'"/>
| Note |
|---|---|
It is important to keep the single quote wrapping 'yes' or 'no' inside the double quote. Omitting these will fail to work. |
Once you have activated this field and restarted xmlBlaster you have one more field when choosing the initial update page looking like the following:
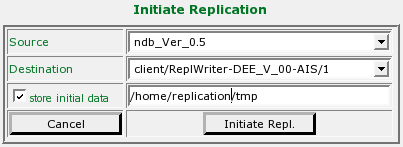
After having initiated the replication with the store initial data checkbox enabled, the initial workflow in the background is basically the same as for a normal initial update with some slight differences. All data is queued as usual, but:
all initial data chunk messages contain a property containing the location where to store such message
After the last chunk two additional end-of-initial-update messages are queued.
In the second phase of the initial update, i.e. when the dispatcher is enabled again for delivery to the slave, the property mentionned above is recognized and the message is not sent to the slave, instead it is written locally on disk at the location you specified.
The two end-of-update messages serve the following purpose: When the first is detected at the delivery step it is not delivered, instead the dispatcher closes again. At this time the first message in the queue will be the second end-of-update message.
The administrator now has to manually copy the files for example on a CD-ROM and deliver it to the slave. On the slave side it has to be copied from the CD-ROM to the location specified by the replication.initialFilesLocation property of the slave.
When the files are on location, the administrator simply activates the dispatcher for that particular slave again and the second end-of-update will be delivered to the slave. On the slave side, when this message arrives, it is detected. Thereby the slave knows it has to search for the messages on the file system and starts to load these files. When the process is successfully ended, the message is acknowledged and the initial update phase is completed.
If an error occurs, the message is not acknowledged, instead an exception is thrown back to the server, the dispatcher is closed again and the error message is visualized in the details pages of that particular slave.
In a normal initial update, the initial data is transfered in chunks to avoid to exceed the maximum size allowed for example if the underlying communication protocol has some restrictions. When using the manual file transfer these chunks are written to file once they are coming in the destination queue. Each of these chunks is then a file on the filesystem. All these files are collected in a subdirectory. The name of the subdirectory is assigned each time an initial update is triggered and is ensured to be unique. In fact it is a unique timestamp.
The name of the chunks is constituted as ${prio}-${timestamp} where ${prio} is the priority of the message and ${timestamp} is the timestamp used to identify the entry in the queue. This way the messages are in the correct order when sorted alphabetically.
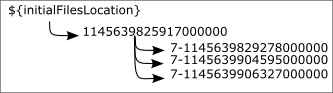
Use the JMX monitor and go to the initialUpdate page. Choose a source and a destination and additionally click the check box store initial data and specify the directory where you want to store your data.
Note The directory where you store your data must exist and it will reside on the machine where the xmlBlaster server is running. On this directory a subdirectory is created. Its name will be a unique timestamp. In that directory all chunks will reside as own files.
Once all entries have come in the queue they will automatically be written to the file system and removed from the queue. At this stage the dispatcher is disactivated and the status stays yellow. In the destinationDetails page (which you access by clicking on the destination name in the destinationList page), you will se in the last message text area the following text: Manual Data transfer: WAITING (stored on '${initialFilesLocation}')
Important If nothing happens here, i.e. if the entries are not written to the file system, verify that the slave is currently online. It must be online as long as the queue has to be flushed to the disk.
Go to the location ${initialFilesLocation}/${subdir} where the ${subdir} is the timestamp generated for this particular initial update. Verify also that this subdir is populated with files.
Copy the entire subdirectory with all its contents to a media of your choice. For example on a DVD or a CD-ROM.
Transport the media to its destination, i.e. the slave on which the data has to be installed.
Copy the subdirectory and all its contents to the directory ${initialFilesLocation}.
Note You have to verify what this location is by consulting the configuration for this particular slave because it could be configured differently than the master.
In the JMX Monitor reactivate the dispatcher for this slave. At this stage a message is sent to the slave. On receiving this message the slave reads the stored files with the initial data. The data is written to the DB and when this process is finished the message is acknowledged and the status turns green, meaning it is now ready and fully online.
In the following sequence diagram the workflow of several operations to be replicated is shown:
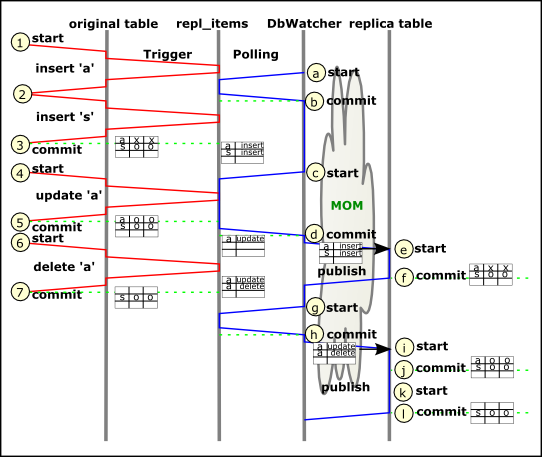
The red lines on the left hand side are the synchronous thread of the caller. These occur inside the database as PL-SQL invocations. The blue lines on the right hand side represent symbolically the publishing thread and the update (or distribution) thread.
On initial update, information about tables to be watched was gathered. Depending on the configuration a trigger was added to the table to be replicated.
When a change occurs on a table to be replicated, the trigger on that table is fired. On Insert, update or delete the trigger ensures that the change is serialized as an xml literal to be stored either in the content or in the oldcontent column of the ITEMS or in both. The entry is then stored in the ITEMS table. Such an approach allows to gather replication data even if the XmlBlaster should be down for some reason. This means that if the xmlBlaster is not available this only delays the replication until the xmlBlaster is available again, but no data will be lost. Now the replication data is temporary queued in this table until it is picked up by the DbWatcher.
As we saw in the previous section, the replication data has been queued in the ITEMS table. It is now the job of the DbWatcher polling thread to detect that something new is available on that table, pick it up, process it, publish it and finally remove the processed data from the queue.
The format of the replication message is conform to the standard format for the DbWatcher. It is specified its XSD Schema. For each transaction one single message is sent. If the transaction is constituted by several writing actions, then the message will contain multiple change actions.
The prepared messages are published by the DbWatcher to the xmlBlaster. All messages are handled persistently, so if a DbWatcher is running standalone and the XmlBlaster is currently unavailable, such messages are queued in a persistent storage. When the XmlBlaster becomes available again queued messages are published. Even for cases where the DbWatcher is running embedded the messages are persistent. This to avoid loss of messages on runlevel changes. When messages are published, i.e. are stored in the persistent queues of all interested slaves, the DbWatcher thread returns and removes the processed messages from the ENTRIES table. On an XmlBlaster crash happening after having successfully published the messages but before removing the entries from the table it could occur that the same change entry is published twice. This is detected later by the DbWatcher and the message is marked to avoid double delivery.
When the DbWatcher is publishing the messages it is not necessary for the real slave to be available since the data is stored persistently on a serverside queue (also called the callback queue). If it is available, or when it becomes available, the message is delivered to the slave if and only if the message is not obsolete. A message can be obsolete if it was already delivered, i.e. if it was marked by the DbWatcher as a double. Messages are also obsolete if they are older of an ongoing initial update. In other cases the message is delivered.
On the slave side, the responsible class taking care of the storage is the DbWriter. The DbWriter is a general purpose class used to store messages on a database. It is a minor plugin framework which makes use of interfaces which can be implemented differently for specific purposes. One of such specific purposes is indeed replication. Therefore the class making the job is the ReplicationWriter.
The ReplicationWriter checks what kind of action it is, performs the necessary filtering and modifications and executes the change on the replica database as a jdbc call. There is the possibility to ignore certain actions, the data content can be modified or the name of the destination tables or the columns can be modified. All this can be configured, and where configuration does not suffice the user can implement its own business-specific code for the available interfaces.
When an exception occurs a check is made to determine what the problem is. On INSERT or CREATE, if an entry was already found, the action is ignored and a warning is written to the logs. If an entry to be updated or deleted is not found, a warning is also issued. Other errors are logged and the exception is thrown back to the server. The server, on receiving the exception temporary stops the delivery to that specific slave client. At this point it is the responsibility of the administrator to analyze the error, fix it, and manually reactivate the delivery.
Table of Contents
There are several different ways to monitor the replication, however there is a monitoring which has been specifically designed for the replication. That's our MX4JAdaptor which invokes a set of xsl stylesheets which make the necessary customization for the replication.
We have a jmx plugin making use of the mx4j http adaptor.
The configuration of the MX4JAdaptorPlugin is done as for the other xmlBlaster plugins in the xmlBlasterPlugins.xml configuration file. The following is an example of such a configuration. The files used for the xsl transformation reside in the directory: ${XMLBLASTER}/src/java/org/xmlBlaster/contrib/replication/monitor.
<plugin id='MX4JAdaptorPlugin' className='org.xmlBlaster.contrib.jmx.MX4JAdaptor'>
<attribute id="xsltProcessor">XSLTProcessor</attribute>
<attribute id="host">localhost</attribute>
<attribute id="port">9999</attribute>
<attribute id="adaptorName">HttpAdaptorMX4J</attribute>
<attribute id="xsltPath">org/xmlBlaster/contrib/replication/monitor</attribute>
<attribute id="xsltCache">false</attribute>
<attribute id="authenticationMethod">basic</attribute>
<attribute id="replication.monitor.user.mike">usrPwd:user</attribute>
<attribute id="replication.monitor.user.james">initPwd:initiator</attribute>
<attribute id="replication.monitor.user.fred">adminPwd:admin</attribute>
<action do='LOAD' onStartupRunlevel='4' sequence='4' onFail='resource.configuration.pluginFailed'/>
<action do='STOP' onShutdownRunlevel='3' sequence='66'/>
</plugin>
Table 3.1. The Items table
| Attribute | Default | Description |
|---|---|---|
| xsltProcessor | null | Normally you need to pass XSLTProcessor here since you want to process the generated xml by our special set of xsl files. For debugging purposes however you can pass null here, in which case the http requests will return the raw xml string. |
| host | 0.0.0.0 | This is the name or ip address of the host. If you pass the default 0.0.0.0 the embedded http server will be listening to all local interfaces. |
| port | 9999 | This is the port number on which the embedded http server listens for requests. |
| adaptorName | HttpAdaptorMX4J | This is the JMX node Name to give to this adaptor. Note that this must be unique which means that if you want to have several plugins you need to have for each a different name. |
| xsltPath | null | You must fill this value otherwise it will not find your xsl stylesheets. The path you specify will be searched in the CLASSPATH you specified when you started the server. If several matching files are found, a warning is issued. |
| xsltCache | true | If you want to disable caching for the xsl stylesheets you could pass false here. This could be usefull to test your own customizations. |
| authenticationMethod | null | The authentication to be used. Currently either null (attribute not defined) or basic are allowed. Basic means the basic authentication popup window is displayed when trying to access the page the first time on a session. |
| replication.monitor.user.* | null | These have only effect if you specified the authenticationMethod. You use it to define the authenticated users. One attribute per allowed user is needed. The value of the attribute is a comma separated list of roles. Allowed roles are user, initiator, admin. The role user is the lowest, i.e. it is only allowed to perform read operations and set the dispatcher to true/false. Other writing operations such as to delete entries from the callback queues, start a replication or remove slaves are not allowed. The role initiator has implicitly the role user and additionally is allowed to initiate a replication. The role admin is allowed to perform all operations. |
The Monitor has three main pages plus some other pages used to display results and errors. Every page has tooltips shortly describing the item's function.
You get this page per default. For example if you point your browser to http://localhost:9999 you will see this page. This page displays the status of each ongoing replication in a table. It is a monitoring page, that is, control operations can not be performed here. This page refreshes automatically with a frequency which is customizable. On this page you don't see replications which have not been initiated yet.
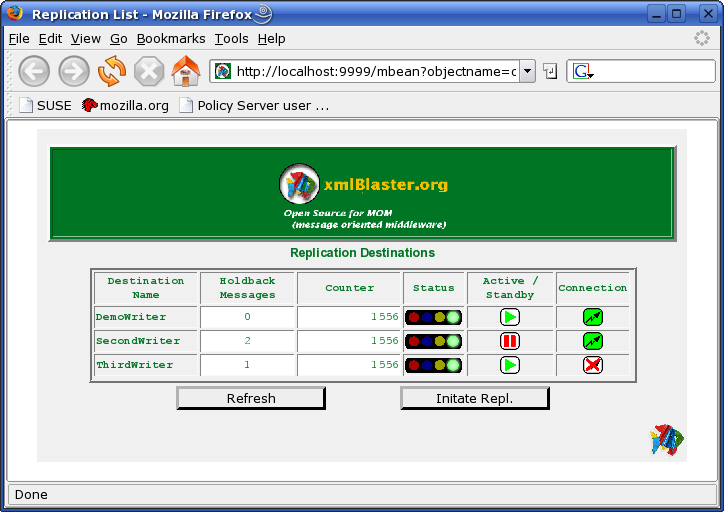
The data is displayed in a table having 6 columns. The first column Destination Name displays the name of the slave associated to that replication. This name is normally either the session name of the slave or a subset of it. This name is customizable. You can click on these names to go to the details of that particular replication.
The Holdback Messages column displays how many entries are still to be delivered. These entries are in the Callback Queue for that client. Under normal operation it should display 0, meaning the holdback queue is empty. There can be three reasons why you have holdback entries:
The server can not contact the slave. This can either be because the connection or/and the slave are down. This can be verified on the column on the left.
The dispatcher delivering the messages from the server side to the client side has been put in standby. This is the case during an initial update as far as the Status is INITIAL (semaphore showing blue). The dispatcher is also put on standby if an exception occurs when writing data in the replica database. This to allow the administrator to repair the error before continuing. The administrator has also the possibility to toggle the state of the dispatcher from active to standby and back.
There are currently many messages to be replicated: more than the slave can handle. This is normally the case during rush hours. It is important that the number of messages in the holdback queue don't grow constantly. If this is the case it means the system is not optimally designed and load balancing or other solutions should be considered.
The Counter column shows the current status of the counter. This is a monoton increasing unique positive integer identifying the message containing the data to be replicated. Be aware of the fact that also internal administrative messages use this counter. This means that in some circumstances there may be entries in the holdback queue which are not containing data to be replicated.
The Status column contains a semaphore having four statuses. One color for each status:
Red is used for the INCONSISTENT. You normally don't see this status. It is the result of an interrupted intial update or if entries have been removed from the callback queue using the administrative console. If you have such a state you need to re-trigger an initial update for that particular replication.
Blue is used for the INITIAL. This is the status indicating that an initial update has been triggered. This will be the status of the replication until all the initial data has been collected and put in the holdback queue. During this phase the dispatcher is in standby mode.
Important During this phase you are not allowed to activate the dispatcher.
.
Note During this phase you also see the amount of holdback messages can increase substantially. This is normal since all entries must be queued before starting to replicate.
Yellow is used for the TRANSITION. During the initial update, once all data has been collected on the holdback queue the status switches from blue to yellow. At the same time you can observe that the dispatcher has switched from standby to active. This is the sign that messages are starting to be delivered to the slave, the slave starts to replicate and the amount of holdback messages diminuishes.
Green is used for the NORMAL operation. This is the most common status. It means the initial phase of the replication is accomplished and diffs are replicated on the fly. During this phase, if the dispatcher is in standby or the connection is broken, the entires are hold back. This is not a problem since when the slave is available again, these messages are all delivered in the correct sequence.
The Active / Standby column shows the status of the dispatcher in charge of delivering the messages from the server side to the slave. It has two statuses, either active, meaning the server tries to deliver the messages, and standby meaning it will not deliver even if the connection to the slave is OK.
The Connection column displays the status of the connection. It also has two statuses: either the communication is OK, meaning the slave can be reached from the server, or not OK meaning either that there is a communication problem (for example no route or disconnected ethernet cable), or the slave is not running. Since monitoring is done on the server side there is no way to distinguish among these two cases.
On the bottom of the page there are two buttons. The left button is used to manually refresh this page. The right Initiate Repl. button takes you to the page where you can initiate a new replication.
This page is used to start a replication for the first time. It basically has two display modus which are configurable in the customize.xsl stylesheet. The default is a simple modus which is determined by the parameter:
<xsl:param name="show.cascading" select="'no'"/>
Or for the advanced case:
<xsl:param name="show.cascading" select="'yes'"/>
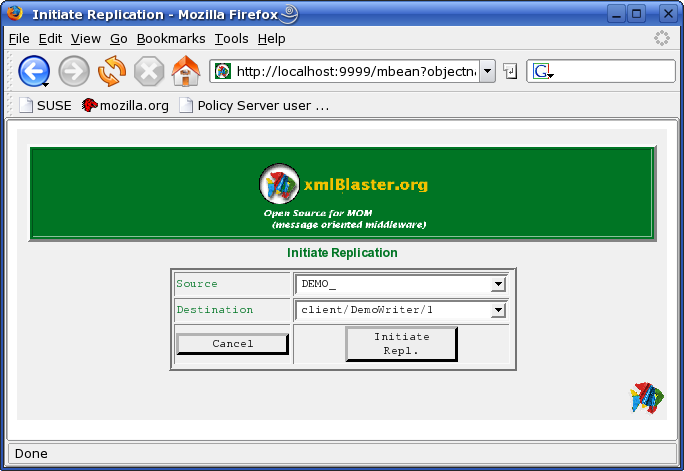
In simple modus there are two multiple choice fields:
The Source field lets you choose which master to use. The Master is identified by the replication.prefix attribute of the DbWatcher acting as master.
The Destination field lets you choose which slave to use. The Slave is identified by the session name of the DbWriter .
As a source you only will see Masters which are registered.
| Note |
|---|---|
When a Master is not accessible, for example in case it is running as a remote application and the connection is temporary broken, it is automatically unregistered. It will be registered again once it will be able to access the XmlBlaster Server again. While unregistered it is not possible to initiate a replication where it is supposed to act as a master. In other words: the master needs to be available at the moment an initial update is triggered. |
As a destination you only will see such DbWriters which have already connected to the XmlBlaster.
| Note |
|---|---|
In contrast to the Master -which needs to be available when initiating a replication- the slave does not need to be available all the time. It suffices that it has connected once to be known (or registered). It will not be unregistered every time the connection is broken. You can start a replication involving a DbWriter even if the connection to this is currently broken. |
Once you have made the choice of a Master and a Slave you can click on the button Initiate Repl. which will start the replication and take you back to the replication list page.
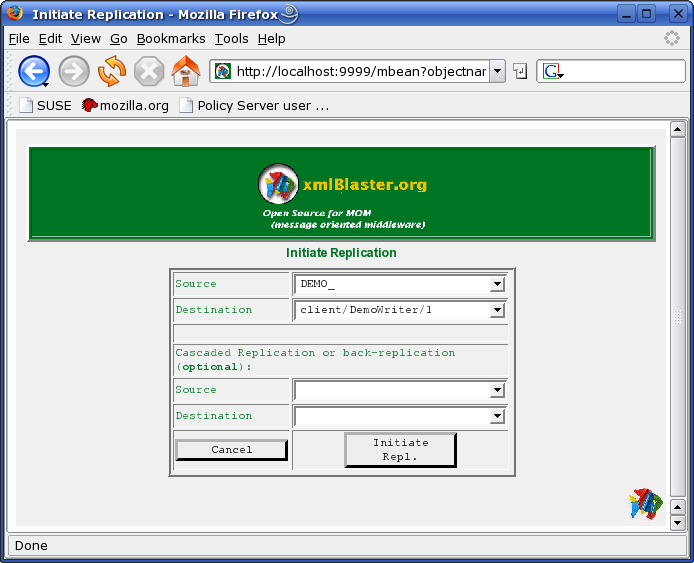
Cascaded modus means you can optionally choose a replication to be automatically initiated once the replication which you trigger now has reached its NORMAL operation status.This can be useful for example for cases where you have a back and forth replication and you don't want to manually trigger the back-replication everytime you want to initiate the replication. If you don't need the cascaded replication leave these fields empty.
| Important |
|---|---|
Once you have made the choice and pushed the Initiate Repl. button the cascaded option is persistently memorized. Subsequently, if you start again the same replication, you don't need to re-specify the cascaded replication: it will be remembered and executed again. |
The Source field lets you choose which master to use. The Master is identified by the replication.prefix attribute of the DbWatcher acting as master.
The Destination field lets you choose which slave to use. The Slave is identified by the session name of the DbWriter .
As a source you only will see Masters which are registered.
| Note |
|---|---|
When a Master is not accessible, for example in case it is running as a remote application and the connection is temporary broken, it is automatically unregistered. It will be registered again once it will be able to access the XmlBlaster Server again. While unregistered it is not possible to initiate a replication where it is supposed to act as a master. In other words: the master needs to be available at the moment an initial update is triggered. |
As a destination you only will see such DbWriters which have already connected to the XmlBlaster.
| Note |
|---|---|
In contrast to the Master -which needs to be available when initiating a replication- the slave does not need to be available all the time. It suffices that it has connected once to be known (or registered). It will not be unregistered every time the connection is broken. You can start a replication involving a DbWriter even if the connection to this is currently broken. |
Once you have made the choice of a Master and a Slave you can click on the button Initiate Repl. which will start the replication and take you back to the replication list page.
If you click on the Cancel button you will be sent back to the replication list page without initiating a replication.
This page shows the details about a single entry. This is not only a monitoring page but also a control page. You can perform several operations on the particular replication.
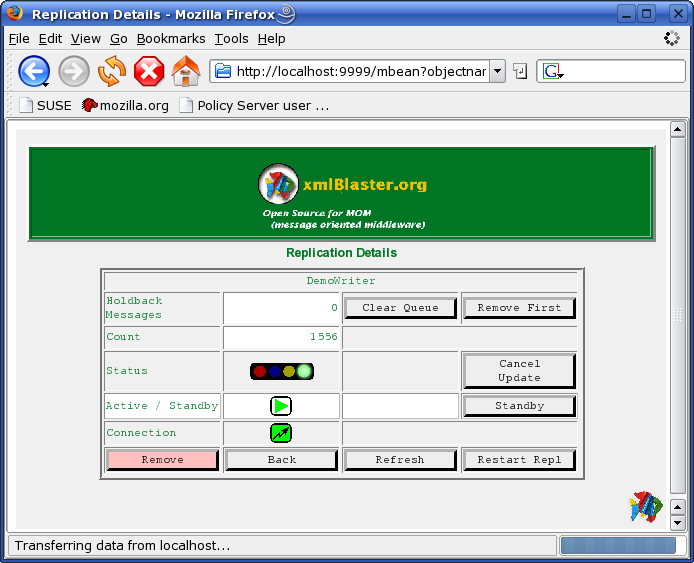
The first column on the left displays the property to monitor/control. The second column from the left displays the current status of that property. This is basically the same information which is also displayed in the replication list page. The rest of the colums display controls used to perform some operations, for example change the status of the property.
Clear Queue This button will clear (remove) all hold back messages. You should use this with care since you will probably get an inconsistent state on the replica after this invocation. Unless you use it to clean up an error, you should re-initiate the replication afterward.
Note The cleaning up of the holdback messages is also automatically done when you intitiate a replication.
Remove First removes the first entry in the holdback queue. This is useful if the last operation produced an error which automatically switched the dispatcher to standby. In such cases, fixing the error on the slave manually, then removing this entry and finally switch the dispatcher to active again will solve the problem and return to normal operations.
Cancel Update is used to stop an ongoing update. This operation is needed if you have previously triggered an initial update which for some reasons did not succeed. This operation will immediately change the status to INCONSISTENT: the semaphore will show red light.
Standby / Activate switches the dispatcher of the holdback messages from active to standby and vice versa. Under normal operations you can safely use this button. Putting it in standby will temporary block the replication for the specific slave.
Important You shall not use this button while not under normal operations.
Remove removes a replication permanently. You normally don't use this feature unless you want to remove forever a certain replication.
Back takes you back to the replication list page.
Refresh manually refreshes this page. This is normally not necessary since the page refreshes automatically.
Restart Repl is used if you want to restart a replication. It remembers the values configured the first time you started the replication for the first time. This has the same effect as going to the Initial Update Page and trigger a replication with the same source and the same destination.
Note Note that the optional cascaded values can be overwritten, i.e. the cascaded replication can be changed but can not be removed.
Table of Contents
Table of Contents
The different modules involved in the replication communicate by means of xmlBlaster messages. In some cases these are PtP messages and in some other cases they are Pub/Sub messages. Basically a message has a metadata part and a content. In the metadata part the relevant part is the Qos (Quality of Service) and more specifically the ClientProperties which contain attributes used internally by the replication.
The replication messages can be divided into two groups: such messages which transport data to be replicated, and such messages which are used for administrative purposes, for example to inform or control one or more modules. The first are refered to as Data Messages while the later as Administrative Messages.
On initial update several messages are sent from the master to the slave. These messages are always intercepted by the ReplManagerPlugin which delegates processing to the ReplSlave.
These messages are only sent if the configuration is such that an export of the database is necessary. The content of these messages can either be xml (where the binary content has been base64-encoded) or in compressed binary format. Since these database dumps can be very large, they are sent chunkwise. The size of these chunks is configurable and per default 1 MB before compression. The message is persistent and published as a PtD (can be multiple destinations) high priority (9) message to the interessed sessions.
Table 5.1. Attributes of Initial Dump message
| Attribute Name | Type | Default | Comment |
|---|---|---|---|
| String | null | Mandatory . It contains the sessionId of the slave which shall receive the data for this initial update. |
Administrative messages contain the command (or action) to be performed in the content of the message. It is a string in upper-case letters.
The following messages are used to control the master of the replication. The master of a Database replication is normally a DbWatcher (either standalone or as a plugin) but the user is free to implement its own module (plugin or application) which will respond to such messages with the adequate actions.
This message is sent by a ReplSlave as a PtP to the session of the associated master to tell him to start a new initial update. The ReplSlave knows the session of the master since it knows his complete configuration. This message is published on the topic replRequestInitialData. The message is persistent and will be queued if the master is not available.
Table 5.2. Message Attributes for REQUEST_UPDATE administrative messages
| Attribute Name | Type | Default | Comment |
|---|---|---|---|
| _slaveName | String | null | Mandatory. It contains the sessionId of the slave which shall receive the data for this initial update. |
| _replVersion | String | null | Mandatory. It contains the version of the source of the replication to be used for this slave. |
| _initialFilesLocation | String | null | Optional. Tells where to store the initial files in case the replication data has to be transfered manually by means of copying files. |
| _initialUpdateOnlyRegister | boolean | false | Optional. If true, the message will inform the master not to start with the initial update right the way. Instead it will accumulate this request with others and wait until a INITIAL_UPDATE_START_BATCH message arrives. Only then it will initiate the update. |
This message is sent by a ReplSlave as a PtP to the session of the associated master to tell him to cancel the previously triggered initial update. The ReplSlave knows the session of the master since it knows his complete configuration. This message is published on the topic replRequestCancelUpdate. The message is persistent and will be queued if the master is not available.
Table 5.3. Message Attributes for REPL_REQUEST_CANCEL_UPDATE administrative messages
| Attribute Name | Type | Default | Comment |
|---|---|---|---|
| _slaveName | String | null | Mandatory. It contains the sessionId of the slave which shall receive the data for this initial update. |
This message is sent by the ReplManagerPlugin as a PtP to the session of the master to tell him to recreate the triggers used to detect changes on the source database. This message is published on an anonymous topic. The message is transient and will be queued if the master is not available. No attributes are used for this command message. This is normally a request triggered on the JMX Console. No confirmation messages are sent back to the publisher of this message.
This message is sent by the ReplManagerPlugin as a PtP to the session of the master to tell him to execute a Statement (an SQL Statement) on the master and all the associated slaves. The statement can either be a read- or write statement (select or update). This message is published on the topic replRequestBroadcastSQL, is persistent and will be queued if the master is not available. A response of the result of the operation on the master is published on the topic specified in this request via a Data Message with command STATEMENT. Also is replicated to all associated slaves using the replication mechanism of the master (normally via its REPL_ITEMS Table. The message can be published as a high prio message (priority 8).
Table 5.4. Message Attributes for STATEMENT administrative messages
| Attribute Name | Type | Default | Comment |
|---|---|---|---|
| statement | String | null | Mandatory. It contains the SQL Statement to be executed. |
| statementPrio | boolean | false | Optional. If it set to true the priority of the responses will be set to be high (8). |
| statementId | String | null | Mandatory. This is the ID which identifies this request. It is used to find the response to the request. |
| sqlTopic | String | null | Mandatory. This is the name of the topic to be used for the responses of the select statement. |
| maxEntries | Integer | null | Optional. This is the maximum number of results to be sent back as the result of the statement. If nothing is specified, the complete result is returned. |
This message is sent by the ReplManagerPlugin as a PtP to the session of the master to tell him to start collect initial update commands. This message is published on the topic replSimpleMessage, is transient and will be queued if the master is not available. It contains no attributes.
This message is sent by the ReplManagerPlugin as a PtP to the session of the master to tell him to start the initial update for the collected requests (all INITIAL_UPDATE requests collected after the last INITIAL_UPDATE_START_BATCH). This message is published on the topic replSimpleMessage, is transient and will be queued if the master is not available. It contains no attributes.
Table of Contents
Table A.1. Properties used for the replication
| Property Name | Where | Type | Default | Comment |
|---|---|---|---|---|
| db.user |  | String | null | This is mandatory for both Master and Slave. Specifies the database user name |
| db.password | | String | null | This is mandatory for both Master and Slave. It is the password used to login to the database |
| db.url |  | String | null | This is mandatory for both Master and Slave. It is the url of the database to use |
| dbWatcher.maxCollectedStatements |  | int | 0 |
Specifying a value here will allow you to send more than one transaction in the same message. This
is useful for cases where performance is a problem. This will speed up replication but can not be used
if transactions occurring on the master have to be reproduced one to one on the slave. If you choose
this option you may choose in your properties (for example in the
xmlBlaster.properties file) the following line:
MimePublishPlugin[ReplManagerPlugin][1.0]=\
org.xmlBlaster.contrib.replication.impl.ReplManagerPlugin
which will allow you to see each transaction in the counters and in the queues. When you choose this
plugin you will not see the messages really queued in the counters of your replication monitor. You will
see a fake representing each transaction. So for example if you have three messages in the queue each
of which containing 3 transactions, you will see 9 entries in the holdback messages
column. If you do not choose this plugin you will see the real messages, loosing this way control over
the number of real transactions generated on the source.
|
| dbWriter.caseSensitive | | boolean | false | Is used on the DbWriter to specify if the comparisons made on the properties have to be done case sensitive or not. You may want to set it to false if your databases are casesensitive and you have objects having the same case-insensitive name. In most cases leave this untouched. |
| dbWriter.prePostStatement.class | | String | (empty) | This is the name of the class to use as an Implementation of the interface I_PrePostStatement. You can write your own implementation and activate it with this property by specifying the name name of your class if you want business specific code to be executed before and after an INSERT, UPDATE or DELETE statement are executed on the Slave. |
| dbWriter.queryImportedKeys | | boolean | true | Setting this value to false will avoid filling the imported key (forein key) information on the writer. Since this info is currently not really used (only for logging and comparison reasons) and since retrieving this information on some databases may be very time consuming it can be switched off. |
| dbWriter.quoteColumnNames | | boolean | false | For cases where the name of a column is a reserved keyword an sql statement could fail. Setting this flag to true will wrap/protect the columnname by a queue. |
| dbWriter.sqlPrePostStatement.sql. ${PREPOST}.${OP}.${SCHEMA}.${TABLE} | | String | (empty) | This properties take effect only if dbWriter.prePostStatement.class was set to org.xmlBlaster.contrib.replication.SqlPrePostStatement. ${PREPOST} can either be pre or post, ${OP} can either be insert, update or delete. ${SCHEMA} is the schema and ${TABLE} is the table name for which the property must take effect. For each defined property the name of a stored procedure is specified as the value. dbWriter.sqlPostStatement.sql.post.insert.XBL.TEST = DUMMY_PROC would for example mean that for every replicated INSERT operation on the table TEST belonging to the schema XBL the stored procedure DUMMY_PROC (which does not take any arguments) will be executed after (since post) the INSERT operation has taken place but still in the same transaction. This allows to execute business specific code directly invoked by the replication. |
| dbWriter.xslTransformerName | | String | (empty) | The name of an optional xsl transformation file. If you specify a file, an xsl transformation of the content of the replication message will be done before any processing done on the slave. Not specifying anything will let the message unchanged. |
| mom.* | | String | null | These properties are normally inherited from the DbWatcher. In this context only the major ones are described. For further details please consult the reference documentation for the DbWatcher and the DbWriter . |
| mom.loginName | | String | DbWriter/1 | Is used on several plugins. For the DbWriterPlugin we can define a comma separated list of values. For each value found in this list, an own instance of a DbWriter is created. For example DbWriter/1, Dummy/2 will create two instances of a DbWriter. The associated mom.password property can in such a case also be expressed as a list of values as for example secretOne, secretTwo. If you only specify one single password, this will be used for both DbWriter instances. The idea of using a list of values permits us to define a single plugin (with one single configuration) for several slaves. Also there is the possibility to add such slaves via jmx in an hotpluggable fashion. |
| mom.password | | String | secret | Is used on several plugins. For the DbWriterPlugin we can define a comma separated list of values. Every entry of the list is mapped to the entries in the list specified in mom.loginName, if less entries are found in the password list, the last value is used for all undefined values. If the number of entries in password is bigger than the number of entries in for the login names, the exceeding passwords are ignored. |
| mom.statusTopicName | | String | null | Name of the topic used on the slave to publish status messages. This is currently unused. |
| mom.topicName | | String | replication. + replication.prefix | Name of the topic on which to publish the replication messages. This is used on the Master. |
| replication.alters | | boolean | true | If set to false entry messages will be ignored and therefore will not be written. This is a slave property |
| replication.bootstrapWarnings | | boolean | false | If set to true, warnings are displayed when bootstrapping. Used on the Master. This flag makes it quite noisy, can be used for debugging purposes. |
| replication.charWidth | | String | 50 | The number of characters used for the normal columns in the tables |
| replication.charWidthSmall | | String | 10 | Number of characters used for columns containing short texts. |
| replication.dbSpecific.class | | String | org. xmlBlaster. contrib. replication. impl. SpecificOracle | The name of the implemenetation class for I_DbSpecific to be used. This class contains the code which is specific to a particular vendor. |
| replication.createDropAlterDetection | | boolean | true | Used on the master to detect CREATE TABLE, ALTER TABLE and DROP TABLE operations. if this flag is set to 'false' such detections do not occur. |
| replication.creates | | boolean | true | Used on the slave to tell if CREATE replication messages have to be executed (true) or ignored (false) |
| replication.drops | | boolean | true | Used on the slave to tell if DROP replication messages have to be executed (true) or ignored (false) |
| replication.forceSending | | boolean | false |
Normally a check is made for messages to be sent to the slave. If such messages are outdated or if the replication key identifying such messages is not monoton incresing it is normally considered an error and messages are not dispatched. For Multimaster approaches this is not true since the replication keys can come from several Masters. For such cases you can disable the check by passing true here. This will mean that messages which are believed to be wrong under a single master perspective are sent anyway. |
| replication.keepDumpFiles | | boolean | false |
If it is set to true, then the file used for the
initial update is not erased after having been processed. This can be useful for debugging purposes.
This flag has only effect if you have a replication.initialCmd string set.
|
| replication.importLocation | | String | ${java.io.tmpdir} |
This is used on the Slave. It specifies where the file used for the initial update is temporary
stored. This flag has only effect if you have a replication.initialCmd string set.
|
| replication.initialFilesLocation | | String | ${user.home}/tmp | This is the location where the data of an initial update is stored per default in case you choose to transfer this data manually per files. The same value is used also to retrieve the data on the slave side. This is an optional field used on both master and slave. On the master it has to be defined on the ReplManagerPlugin. |
| replication.initial.stringToCheck | | String | rows exported | The string to be used to see if the export command in the initial update was
successful. If the string is found, it is assumed to be successful. This is used for external
processes executed within our Master java process does which do not return their error code correcty.
This flag has only effect if you have a replicatin on.initialCmd string set.
|
| replication.initialCmd | | String | null | If set the code is executed as a child process. This is normally a batch job. For examle it could be an export (or dump) of a database. Used on both Master and Slave. |
| replication.initialCmd.sleepDelay | | long | 10L | The sleep delay in milliseconds to wait when checking for new entries in the log buffer. This has only effect if an initialCmd will be used. Tests show that not using a delay may use unnecessary CPU. This is a tuning parameter. |
| replication.initialDataTopic | | String | repl.initialData | If set, the same topic will be used to send the initial data. This slightly saves resources (since the same topic will be reused) and keeps logs cleaner. |
| replication.initialDumpAsXml | | boolean | false | If set to true, it will send the initial dump as a (big) xml. This has an additional overhead since the content must be base64 encoded, increasing the size of the initial update by 33 %. It should only be used if you need xml compatibility not only for updates but also for the initial dump. Choosing this flag automatically reduces the real payload of the chunk by 33 %, i.e. the replication.initialDumpMaxSize of the raw content (before base64 encoding and after base64 decoding) will be maximally 66 % of what specified in order to keep the chunk size once encoded more or less the same. |
| replication.initialDumpMaxSize | | int | 1048576 | This is the maximum size of the chunks of the initial update dump. If the content of the database export is bigger than this size, it will be sent as multiple chunks, each chunk being maximum the size specified here in bytes. |
| replication.mapper.class | | String | org. xmlBlaster. contrib. replication. impl. DefaultMapper | The name of the class to use to make the mapping between source database and destination database. This class can map the name of a schema to another, the name of a table to another or the name of a column to another. |
| replication.mapper.column.* | | String | null |
Used to map columns. This is a prefix, not a complete name. You can define several such mapping entries, one for each column you have to map. The syntax for the name of such properties is the prefix replication.mapper.column. added with ${schema}.${table}.${column}. As value you specify the name to be used for that column on the Writer side: only the bare column name without any schema or table name. Used on the Slave. Has only effect if you use the DefautMapper. |
| replication.mapper.schema.* | | String | null |
Used to map schemas. This is a prefix, not a complete name. You can define several such mapping entries, one for each column you have to map. The syntax for the name of such properties is the prefix replication.mapper.schema. added with ${schema}. As value you specify the name to be used for that schema on the Writer side.Used on the Slave. Has only effect if you use the DefautMapper. |
| replication.mapper.table.* | | String | null |
Used to map tables. This is a prefix, not a complete name. You can define several such mapping entries, one for each table you have to map. The syntax for the name of such properties is the prefix replication.mapper.table. added with ${schema}.${table}. As value you specify the name to be used for that table on the Writer side: only the bare table name without any schema name. Used on the Slave. Has only effect if you use the DefautMapper. |
| replication.maxRowsOnCreate | | int | 250 |
The maximum number of rows (entries) to be sent in one single message when a CREATE operation has been
detected. This has only effect if |
| replication.monitor.statusPollerInterval | | long | 5000 |
The poller interval for updating the data exposed to the JMX Monitor in ms. Note that this is not the refresh rate of the monitor itself. The refresh rate is specified in the customize.xsl file as the property refresh.rate. The property statusPollerInterval controls a background thread which updates the data exposed. This approach has been choosen because there are properties which synchronize objects when invoking their getter method. This would result in the monitor being blocked while shuch operations are ongoing and in some case it could result in lock up. Worth to know is that there is only one single thread for all slaves keeping this way resource consumption low even when choosing lower values for this property. This is a property which has to be defined on the ReplManagerPlugin. |
| replication.oracle.wipeoutFunctions | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Functions of this schema will be deleted if true. |
| replication.oracle.wipeoutExIfConnected | | boolean | false |
Used only on oracle. On initial updates, before cleaning up all resources belonging to the schema to wipe out an exception will be thrown if you specify true and there still are users logged in to that schema. If you specify false only a warning will be logged. |
| replication.oracle.wipeoutIndexes | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Indexes of this schema will be deleted if true. |
| replication.oracle.wipeoutPackages | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Packages of this schema will be deleted if true. |
| replication.oracle.wipeoutProcedures | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Procedures of this schema will be deleted if true. |
| replication.oracle.wipeoutSequences | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Sequences of this schema will be deleted if true. |
| replication.oracle.wipeoutSynonyms | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Synonyms of this schema will be deleted if true. |
| replication.oracle.wipeoutTables | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Tables of this schema will be deleted if true. |
| replication.oracle.wipeoutTriggers | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Triggers of this schema will be deleted if true. |
| replication.oracle.wipeoutViews | | boolean | true |
Used only on oracle. On initial updates, before importing the data the Views of this schema will be deleted if true. |
| replication.overwriteTables | | boolean | false | If set to true it will overwrite a table even if a table exists at the time a replication message wants to create the same table again. Per default however it will get an error and the disactivate the delivery of messages to the involved Slave. It is then the responsability of the administrator to remove the error and activate the delivery again. |
| replication.path | | String | ${user.home}/tmp |
Tells where to temporary store the data to be sent to the slave during an initial update. This has only
effect if replication.initialCmd was used.
|
| replication.plsql.debug | | boolean | false | used to debug the PL/SQL Code in triggers and functions. Used on the Master. |
| replication.plsql.debugFunction | | String | null | used to debug the PL/SQL Code in triggers and functions. Used on the Master. |
| replication.prefix | | String | repl_ |
Has mainly two purposes: the first is to identify the source of the replication (the Master).
The second purpose is to be used as a prefix for all resources used in the database for the replication.
For example if you specify here DEMO, then the ITEMS table will
be called DEMOITEMS.
|
| replication.prefixGroup | | String | ${replication.prefix} | It has the purpose to identify a group of replication sources. This way if you choose to have an own implementation of the monitor you can group the replications the way you want and monitor such groups in different pages. Used on the Master. |
| replication.recreateTables | | boolean | false | Setting this property to true will overwrite (i.e. make a drop table) the table when a create operation is replicated. When doing so the complete old content of the table is lost. This flag has only effect if replication.creates is set to true. |
| replication.searchable.* | | String | null |
Used to overwrite the default search mechanism used on the slave when updating or deleting entries. If nothing is specified here, when an update or a delete operation is replicated, the entry to update or delete is searched in the destination database. If the table has primary keys defined, these primary keys are the only columns used for the search. If the table has no primary keys, all searchable columns are used in a SELECT .. WHERE ... AND statement. This can be timeconsuming and it does not allow the user to change such columns on the destinations. Here you can define which columns have to be used to search. An example: replication.searchable.XMLBLASTER.TABLE1=COL1,COL2 would update the entry which meets the SELECT XMLBLASTER.TABLE1 WHERE COL1='aaa' AND COL2='bbb' statement (here aaa and bbb are the values to be searched). In the example XMLBLASTER is the schema and TABLE1 is the table name. If such a configuration is specified for a given table, then it is used even if the table has primary keys defined, however a warning is output on its first usage. If you specify a column which is not searchable, a warning is written and the inherent column is not used for the search. If you specify a column which does not exist, a warning is output but the entry is still considered in case the column is added later. The key of the property has the syntax replication.searchable.${schema}.${table} and the value is a comma separated list of column names used for the search. |
| replication.sendInitialTableContent | | boolean | true | If true, on a CREATE event, all contents of the table are sent. |
| replication.sendUnchangedUpdates | | boolean | true | If false, on an UPDATE event the old content is compared with the new one. If is then only sent if the two differe from each other. |
| replication.sqlMaxEntries | | long | 10 | This is the maximum number of Entries in the responses of the SQL Statements. Has to be defined in the ReplManagerPlugin. |
| replication.sqlTopic | | String | null | currently unused. |
| replication.statements | | boolean | true | If set to true statements are executed on the slave. |
| replication.writer.schemaToWipeout | | String | null |
The name of the schema to be wiped out during an initial update. Wiping out the schema is
necessary in cases an import operation takes place in the command specified in
replication.initialCmd. The wipeout is executed just before executing
the initial command. Used on the Slave.
|
| table.* | | String | null |
The syntax for the key is table.${catalogName}.${schemaName}.${tableName} where the catalog and the schema are optional while the table name is mandatory. The syntax of the values is actions=${actions},trigger=${triggerName},sequence=${seq} where all arguments are optional. The ${actions} can be a combination of the three characters IDU where I stands for Insert, D for Delete and U for update. These are the actions which have to be replicated. The ${triggerName} is an optional name for the trigger to be added, if you don't specify anything the application will try to assign a valid name for it. Be aware that the length of the trigger name may be limited. Consult the documentation of your DB for this. The ${seq} is an integer telling at which sequence this table will be replicated on initial updates. Low numbers will come first. All tables which have no specified sequence will come in a random sequence (a simple check is made against foreign keys to avoid incosistencies) after the tables for which a sequence number has been explicitly assigned. |
| transformer.class | | String | (empty) | An optional class used to make additional transformation to the message to be delivered. It can for example add attributes to the content of the message on a description- or on a row level. Transformations done by this class will affect all destinations of that replication. |
| wipeout.schema | | String | null |
Used in the main method of the SpecificDefault class. So it can be run as a standalone application.
If you invoke
java -Dwipeout.schema=XMLBLASTER org.xmlBlaster.contrib.replication.impl.SpecificDefault
it will delete all objects belonging to the XMLBASTER schema.
|
- : on master
- : on slave